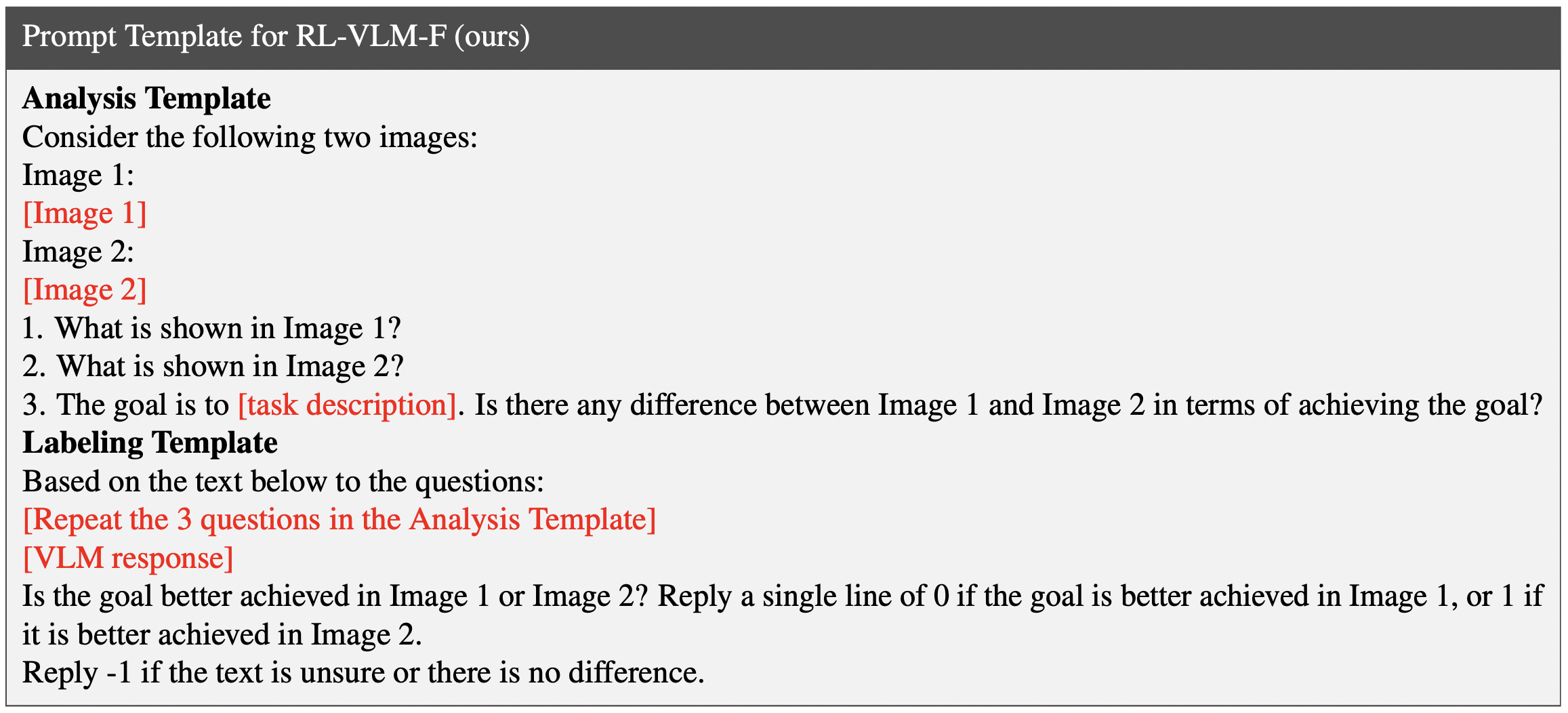
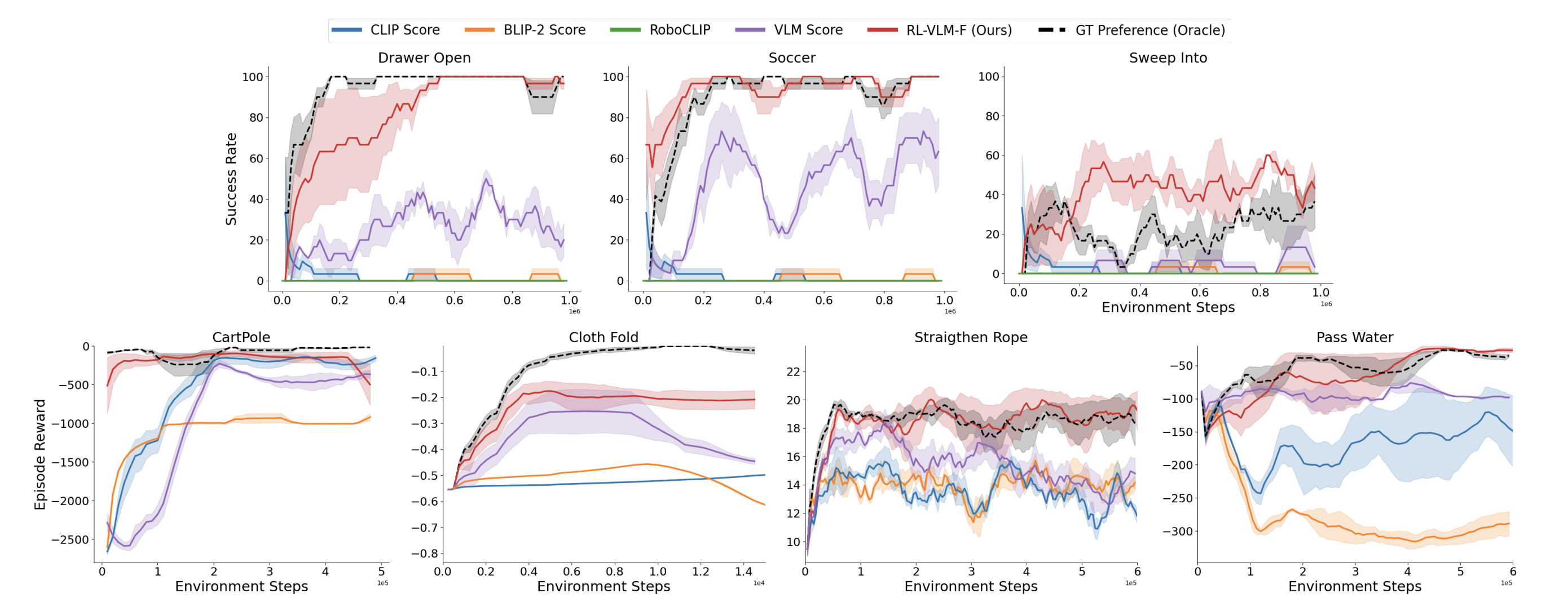
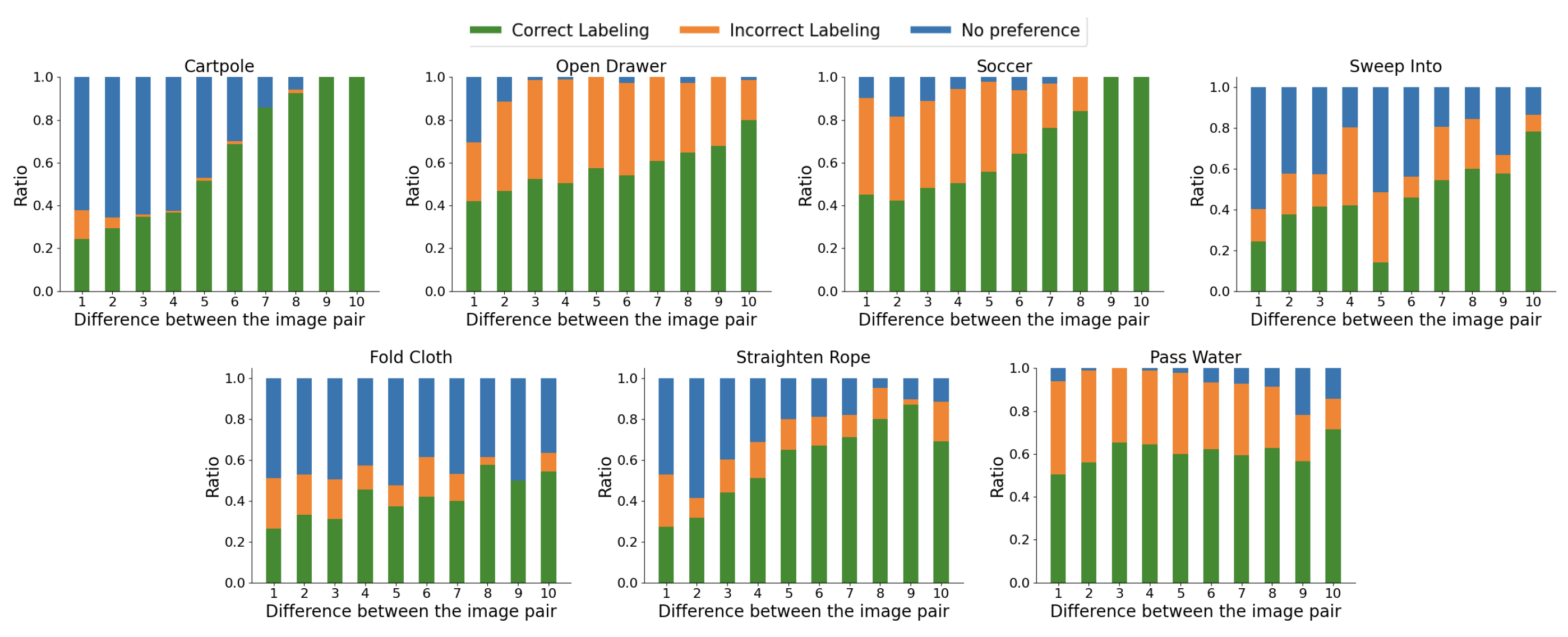
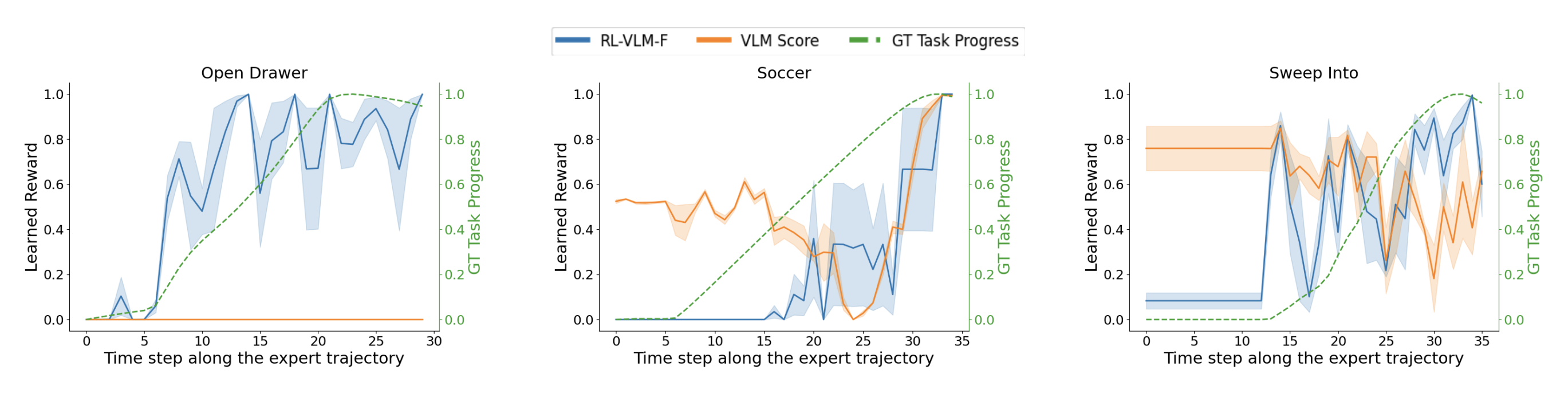
RL-VLM-F Components
Overview: RL-VLM-F automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent’s visual observations, by leveraging feedback from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent’s image observations based on the text description of the task goal, and then learn a reward function from the preference labels. We use Preference-based RL to learn the policy and reward function at the same time.
RL-VLM-F Query Design
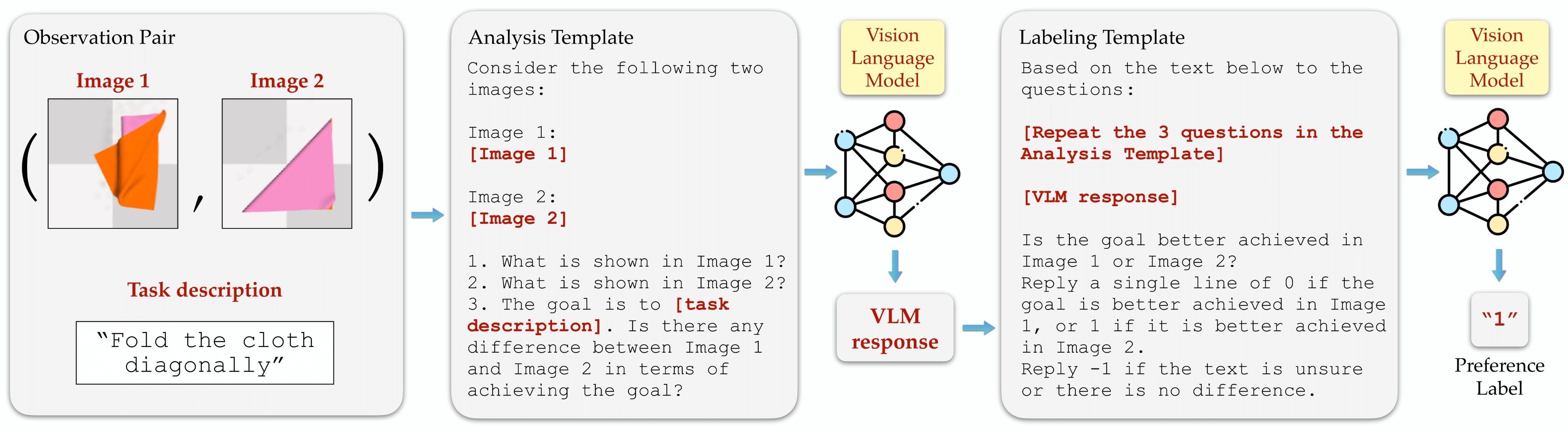
RL-VLM-F Two-stage query: We query the VLM in 2 stages: First, we query the VLM to generate free-form responses comparing how well each of the two images achieves the task. Next, we prompt the VLM with the text responses from the first stage to extract a preference label over the two images. We use the same query template for all tasks, with [task description] replaced by task-specific goal description.